-
-
Benchmark Leaderboard
-
Security Agent Infra
-

ECVE Bench Stack
-

How you should feel, with our project


Inspiration
Cyberattacks on software — particularly the open-source supply chain — have accelerated sharply in the past few years in both frequency and scale. Software and software teams were not built for a world in which malicious actors have access to more capable and more available agent intelligence than ever before.
In the past year alone, over 60% of US businesses and millions of machines were affected by some form of software supply chain attack. In the worst cases, major businesses like Mercor suffered extreme data leaks with incidents propagating through supply chains like NPM.
Current solutions were not built with agents in mind, neither offensively nor defensively. Codebreaker was built to level the playing field and to enable developers to proactively defend themselves against new, increasing threats.
What it does
Codebreaker is an end-to-end cybersecurity platform that pushes the frontier of what AI agents can do in security workflows.
Where existing benchmarks like CyberGYM narrowly focus on memory-safety bugs in C/C++, Codebreaker measures real-world vulnerability detection across the full modern threat landscape — and pairs that benchmark with an agent harness and autonomous patching loop that turn evaluation into action. Our system has three core features:
Frontier benchmark, built for the modern stack: Codebreaker's benchmark, ECVE-Bench (Expansive CVE Bench), is grounded in the GitHub Advisory Database and spans the MITRE CWE Top 25 — covering injection attacks, auth bypass, deserialization, race conditions, and beyond, across every major language and ecosystem. Each benchmark task is a real vulnerability with a real patch, served at four difficulty layers (L0 pure discovery → L3 targeted hint) so the same record cleanly measures everything from open-ended hunting to assisted triage. ECVE-Bench better represents the modern security landscape — enabling it to push the frontier as one of the most extensive and realistic CVE benchmarks available.
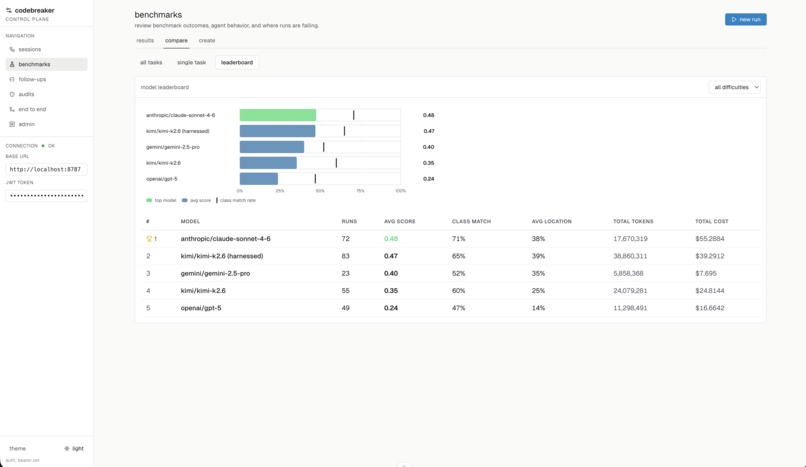
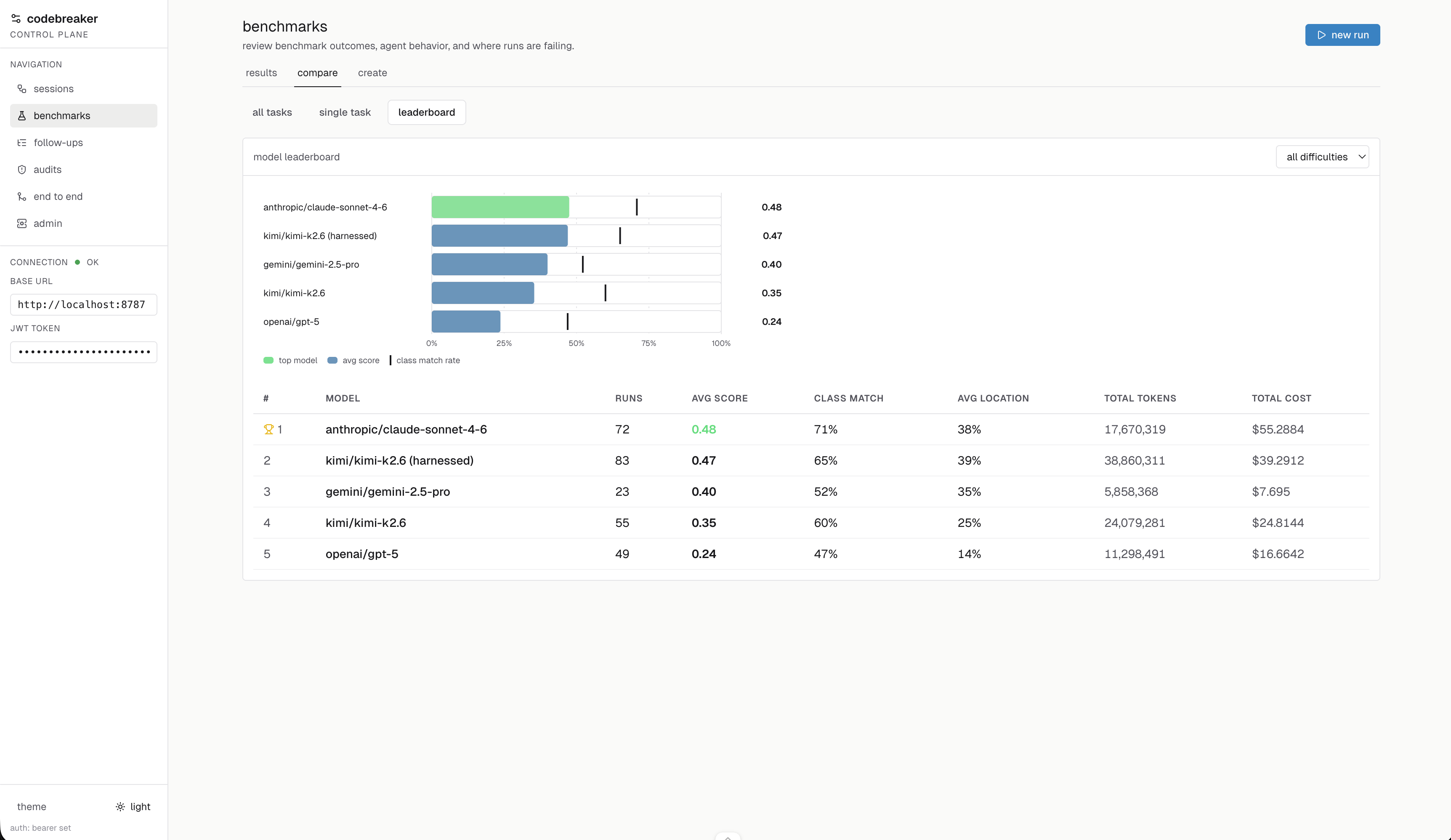
Our benchmark processed over 280 million tokens over 36 hours, thoroughly evaluating the capabilities of frontier models, which we determine to still be limited in cybersecurity.

We find that ECVE Bench is indeed a challenging benchmark for frontier models, with GPT 5 only achieving an average of 24% per benchmark task. Further, we confirm that our harness enhances model capability, with Kimi K2.6 improving from 35% to 47% (a 34% improvement) when embedded within our harness. This approaches the performance of Claude Sonnet, which scored a 48%.

Agent harness specialized for security work: General-purpose models underperform on security tasks because they lack the right context, instincts, and tooling. Codebreaker's harness equips frontier models with tailored prompts, security-specific skills, and purpose-built tools — repo navigation, CVE lookup, exploit reasoning aids — so they can think like vulnerability researchers rather than generalist engineers. The harness is the lever that turns raw model capability into security competence.

Autonomous remediation, via Devin: Identifying a vulnerability is only half the job. Codebreaker integrates Devin to drive the full loop — once a candidate vuln is surfaced, Devin reproduces it, validates the exploit against the vulnerable commit, and generates a fix, accelerating security responses.
Altogether, Codebreaker grounds frontier model capability against the realities of modern software security — creating an adaptive system that finds, proves, and fixes vulnerabilities alongside security teams.
How Devin (Cognition) powered Codebreaker
Devin wasn't just a tool we integrated — it was the force multiplier that made the entire project possible in a hackathon timeframe. It showed up in three distinct, compounding ways:
Devin curated the benchmark. ECVEBench's scale — hundreds of real-world GHSAs across npm, pip, maven, go, and beyond, balanced across the MITRE CWE Top 25 — would have taken a small team weeks to produce manually. Instead, our pipeline filters and stratified-samples advisories from the GitHub Advisory Database, then dispatches each candidate to a Devin session that clones the repo, reads the patch diff, localizes the vulnerability, writes the L0–L3 hint variants, and opens a PR with the curated task and metadata. Every task is reviewable as a normal PR, and when we improved the curation prompt we re-ran Devin in batched, shared-branch mode to refresh the dataset in place. The benchmark we're shipping is, end-to-end, a Devin-produced artifact.
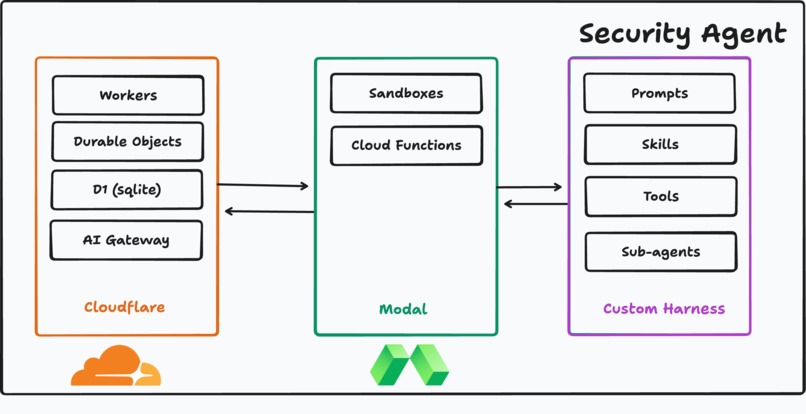
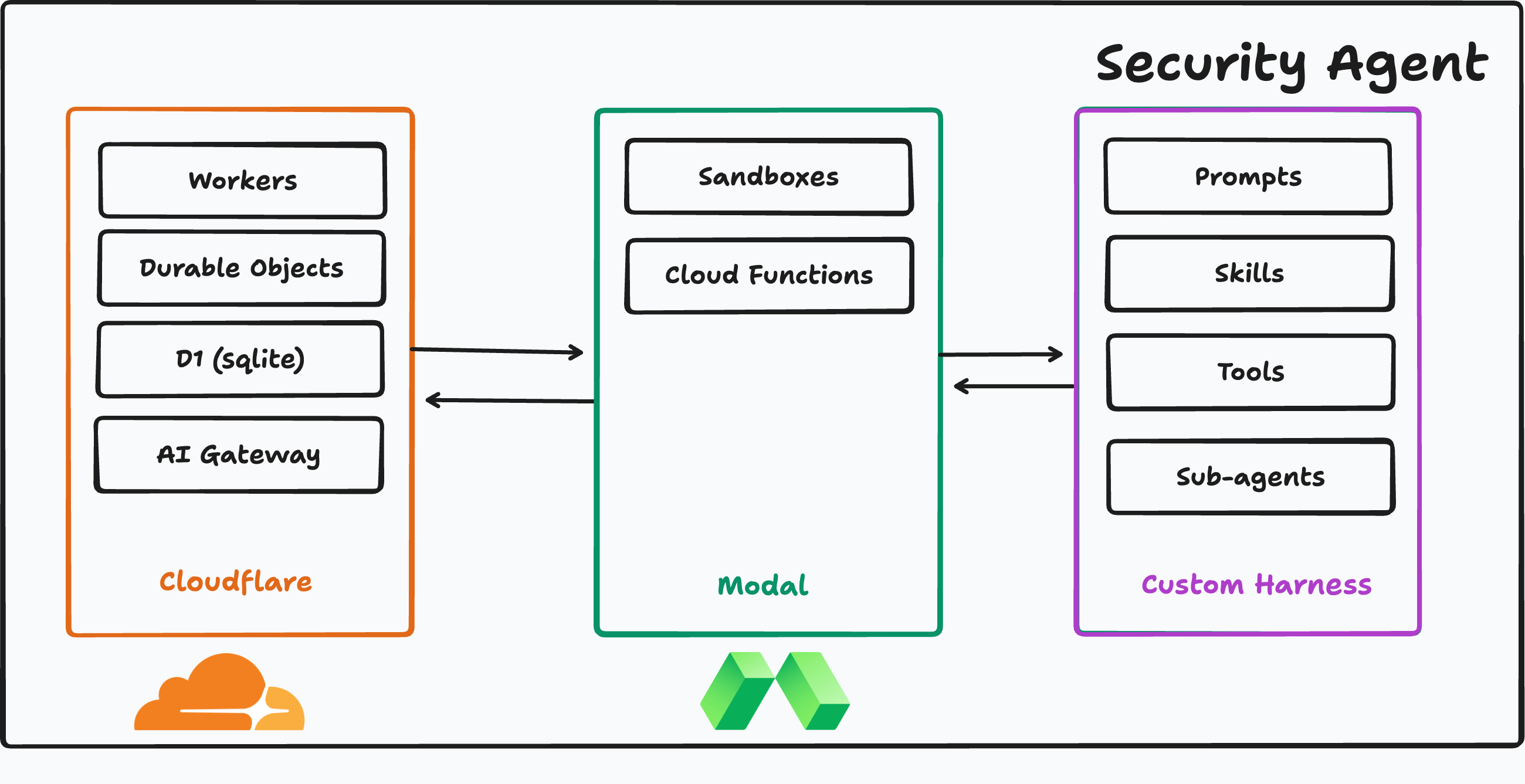
Devin enabled rapid creation and iteration of our harness. The Codebreaker control plane, agent harness, runner, and dashboard — Cloudflare Workers + Hono + D1 + Drizzle, Modal sandboxes, the Vercel AI SDK across Anthropic / OpenAI / Google, and a React 19 + Vite + Tailwind + shadcn frontend — came together in under 36 hours because Devin worked alongside us as a collaborator. We farmed out parallel slices of the system to Devin sessions while we focused on architecture, schema design, and scoring. Maintaining and improving it during the build (migrations, refactors, prompt iterations, audit pipelines) was a continuous conversation with Devin, which is why the codebase has the surface area of a much larger team's project.
Devin powers the autonomous triage loop. Detection is only half the value, and Devin is what closes the gap. When the audit pipeline produces a candidate finding, the CVE follow-up orchestrator hands it off to a Devin session that reproduces the issue against the vulnerable commit, writes a regression test, generates a patch, validates that the fix neutralizes the exploit while preserving behavior, and opens a PR on the affected repository through GitHub. The output isn't a dashboard alert — it's a merge-ready pull request that drops directly into existing software workflows. Without Devin's ability to run long-horizon, multi-step engineering work autonomously, this loop wouldn't exist.
In short: Devin curated our data, built our system, and is the agent at the heart of a critical feature. Codebreaker is what becomes possible when an autonomous engineering agent isn't just an integration — it's a co-author of the entire stack.
Devin is a very hard worker



How we built it
Codebreaker is a full system for evaluating, validating, and patching CVEs. Its three pillars — the benchmark, the agent harness, and the autonomous loop — sit on top of a single control plane that ties model providers, sandboxed execution, and GitHub workflows together.
Benchmark — ECVEBench, curated by Devin.
We didn't hand-curate ECVEBench. We built a three-stage pipeline that filters, samples, and dispatches GHSA records to Devin agents, which do the heavy curation work in parallel:
- Filter: paginates the GitHub Advisory Database for reviewed GHSAs and applies metadata-only filters (CVSS present, English description, single affected package, has commit/PR/tag references).
- Select: maps CWEs to our 13 vulnerability classes via a hand-tuned lookup table, applies a CVSS floor, and stratified-samples across classes so no category dominates.
- Dispatch: hands each candidate to a Devin session with a fully-populated curation prompt. The agent clones the repo, reads the patch diff, localizes the vulnerability to specific files and functions, writes the L0–L3 hint variants, and opens a PR containing both the public task JSON and an internal metadata file.
The result is a benchmark whose scale — hundreds of curated, real-world GHSAs across npm, pip, maven, go, and more — would have been infeasible to produce manually. Each task is reviewable as a normal PR, so curation quality is auditable end-to-end.
Agent harness — Cloudflare Workers, TypeScript, Modal, React
The harness is what every model under evaluation actually runs inside. It's built as a TypeScript monorepo:
Control plane on Cloudflare Workers:
Every benchmark run, audit, and Devin loop is journaled so we can replay and score them deterministically. Multi-provider model layer: built on the Vercel AI SDK with Anthropic, OpenAI, and Google providers behind Cloudflare's AI Gateway, so the same harness evaluates frontier models from every major lab on identical tasks. Tailored tools and skills (packages/control-plane/src/tools): security-specific tools (DeepWiki for codebase Q&A, scoped HTTP, audit-finding submission, benchmark-submit, Modal-backed sandbox tools) wired into tiered toolsets so each agent gets exactly the surface area it needs — no more, no less.
Modal Sandboxes:
every agent action that touches code — cloning a repo, running greps, executing PoCs — happens inside an isolated Modal container. This lets us safely run model-generated commands against vulnerable software without putting the rest of the system at risk. Dashboard (apps/dashboard): a React 19 + Vite + Tailwind 4 + shadcn UI streaming live agent traces, tool calls, and benchmark scores via Cloudflare Agents over WebSockets. Researchers can watch a model triage a CVE in real time, drill into per-tool spans, and compare runs side-by-side. The loop — Devin + GitHub, integrated into real software workflows Identifying a vulnerability is only valuable if the fix actually ships. Codebreaker's CVE follow-up loop (packages/control-plane/src/cve-followup) closes that gap by treating Devin and GitHub PRs as first-class agents in the system:
Autonomous Loop:
The control plane's audit pipeline produces a candidate finding (with file/function localization and a reasoned report). Triage scores and de-duplicates findings; enrichment attaches CVE/GHSA context, CWE class, and patch metadata.
Devin handoff launches a Devin session with a prompt template that asks it to reproduce the issue against the vulnerable commit, write a regression test, generate a patch, and verify the fix neutralizes the exploit while preserving behavior.
GitHub integration: Devin opens a PR on the target repo with the patch, repro, and validation evidence. The PR is the artifact — reviewable, mergeable, and indistinguishable from a human-authored security fix. Because the output is a normal PR, Codebreaker drops directly into existing software workflows. Security teams don't need a new dashboard or ticketing system — they review a PR, run CI, and merge.
Challenges we ran into
- Curating a benchmark at scale. Hand-curating hundreds of CVEs across a dozen ecosystems wasn't feasible, so we built a Devin-driven pipeline to do it for us — and retuned the curation prompt enough times that we had to add a re-curation flow.
- Stitching Workers, Modal, Devin, and GitHub into one durable, sandboxed loop. Each runtime has its own state model, and safely running model-generated exploit code while keeping every benchmark run replayable took serious plumbing.
Accomplishments that we're proud of
- Built an extensive open CVE benchmark, spanning the MITRE CWE Top 25 across npm, pip, maven, go, and more — curated by Devin itself, with every task landing as a reviewable PR.
- Closed the loop from detection to merge-ready patch, evaluating frontier models from every major lab apples-to-apples through a single TypeScript harness.
What we learned
- Tools and prompts are a real lever on capability — the same frontier model performs very differently with a security-tailored harness than with a generic coding loop.
- PRs are the right interface for security work, because every downstream concern (review, CI, merge, audit) is already solved by the tools teams use.
What's next for Codebreaker
- Scale ECVEBench and publish leaderboards across difficulty levels for every frontier model, with deeper static analysis and multi-agent coordination in the harness.
- Wire Codebreaker into live repos so newly disclosed CVEs are automatically reproduced, patched, and PR'd back upstream — the path from benchmarking to zero-day discovery.
Built With
- cloudflare
- devin
- github
- modal
- react
- typescript











Log in or sign up for Devpost to join the conversation.